Version 2.7 adds support for Kayah Li, Lepcha, Ol Chiki, Saurashtra, Shan, Sundanese, and Vai. Full width characters are now accepted in Western numbers.
This is a library for converting Unicode strings to numbers and numbers to Unicode strings. Standard functions like strtoul, strtod, and sprintf do this for numbers written in the usual Western number system using the Indo-Arabic numerals, but they do not handle other number systems. The main functions take as input a UTF-32 Unicode string and compute the corresponding unsigned integer. For example, they will convert the Chinese string 五十九万四千三百二十一 to the integer 594,321 and the Devanagari string ७८४९२ to the integer 78,492. Internal computation is done using arbitrary precision arithmetic, so there is no limit on the size of the integer that can be converted.
The value of the string is returned in one of three forms. One option is a string of ASCII characters containing the decimal representation of the integer using the Indo-Arabic digits. This option has the virtue of avoiding any possibility of overflow or truncation. The second option is to obtain the value as a GNU MP mpz_t object. This is only useful if you are going to do further computation using GNU MP. The final option is to obtain the value as an unsigned long integer. If you are going to do internal calculations, this is probably the most convenient option, but some numbers (in fact, infinitely many) will not fit into an unsigned long integer. The library guarantees that no overflow or truncation will occur; if the number will not fit, it sets an error flag and returns 0.
An inverse function accepts as input an unsigned long integer, an mpz_t object, or an ASCII decimal string and converts it to a Unicode string in a selected number system.
If you use the library, I would be interested in knowing what you are using it for. My own application is in my sort utility msort.
In addition to the library, the command-line program numconv is provided both as an example of use of the library and as a utility possibly of use in its own right. In addition to the number system conversions that are its main use, numconv provides a convenient way to delimit numbers generated by other programs without delimitation or with delimitation inappropriate for the locale. To do this, set both input and output to Western numbers and either set the output delimitation parameters directly on the command line or use the -L flag to obtain them from the locale. For example, both:
echo "123456789" | numconv -f Western_Lower -t Western_Lower -g 2 -G 3 -s ' '
and
echo "123,456,789" | numconv -f Western_Lower -t Western_Lower -g 2 -G 3 -s ' '
will produce the output:
12 34 56 689which might be appropriate in an Indian locale.
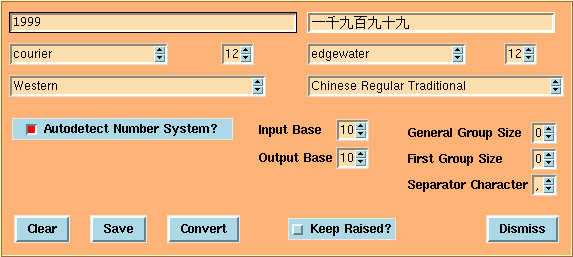
There is also a graphical number converter, NumberConverter, which performs a similar function to numconv.
The number systems currently supported (with some variants omitted) are the following. (Unless you have an unusually comprehensive set of fonts, your brower will not display all of them.)
| Aegean | 𐄝𐄓𐄌 |
| Arabic | ٥٤٦ |
| Arabic Alphabetic | ثمو |
| Armenian Alphabetic | ՇԽԶ |
| Balinese | ᭕᭔᭖ |
| Bengali / Assamese | ৫৪৬ |
| Burmese | ၅၄၆ |
| Chinese | 五百四十六 |
| Chinese Accounting | 伍佰肆拾陸 |
| Chinese Counting Rods | 𝍤𝍬𝍥 |
| Chinese Place | 五四六 |
| Chinese Suzhou | 〥〤〦 |
| Common Braille | ⠑⠙⠋ |
| Cyrillic Alphabetic | ФМЅ |
| Devanagari (Hindi, Marathi, Sanskrit) | ५४६ |
| Egyptian (hieroglyphic) | |
| Ethiopic | ፭፻፬፲፮ |
| Ewellic Decimal | |
| Ewellic Hexadecimal | ` |
| French/Czech Braille | ⠱⠹⠫ |
| Georgian (Mxedruli) | ფმვ |
| Georgian (Xucuri) | ႴႫႥ |
| Glagolitic Alphabetic | ⰗⰍⰅ |
| Greek Alphabetic | ΦΜϚ |
| Gujarati | ૫૪૬ |
| Gurmukhi | ੫੪੬ |
| Hebrew | רתמו |
| Hexadecimal | 0x222 |
| Hungarian Runes | |
| Kannada | ೫೪೬ |
| Kayah Li | ꤅꤄꤆ |
| Kharoshthi | 𐩀𐩀𐩃𐩅𐩅𐩆𐩀𐩃 |
| Khmer | ៥៤៦ |
| Klingon | |
| Lao | ໕໔໖ |
| Lepcha | ᱅᱄᱆ |
| Limbu | ᥋᥊᥌ |
| Malayalam | ൫൪൬ |
| Mongolian | ᠕᠔᠖ |
| New Tai Lue | ᧕᧔᧖ |
| Nko | ߅߄߆ |
| Ol Chiki | ᱕᱔᱖ |
| Old Italic | 𐌣𐌣𐌣𐌣𐌣𐌣𐌣𐌣𐌣𐌣𐌢𐌢𐌢𐌢𐌡 𐌠 |
| Old Persian | 𐏕𐏕𐏕𐏕𐏕 𐏔𐏔 𐏒𐏒𐏒 |
| Oriya | ୫୪୬ |
| Osmanya | 𐒥𐒤𐒦 |
| Perso-Arabic | ۵۴۶ |
| Phoenician | 𐤙𐤙𐤙𐤙𐤙𐤘𐤘𐤘𐤘𐤖𐤖𐤖𐤖𐤖𐤖 |
| Roman numerals | DXLVI |
| Russian Braille | ⠢⠲⠖ |
| Saurashtra | ꣕꣔꣖ |
| Shan | ႕႔႖ |
| Sinhala | ෫෬ |
| Sundanese | ᮵᮴᮶ |
| Tamil Place | ௫௪௬ |
| Tamil Traditional | ௫௱௪௰௬ |
| Telugu | ౫౪౬ |
| Tengwar (mortal) | |
| Tengwar (Elvish) | |
| Thai | ๕๔๖ |
| Tibetan | ༥༤༦ |
| Vai | ꘥꘤꘦ |
| Verdurian | |
| Western | 546 |
Ewellic, Klingon, Tengwar, and Verdurian do not have official Unicode encodings. The library assumes that they are encoded in the Private Use Area in accordance with the encodings registered with the Conscript registry. The Hungarian Runes do not yet have an official Unicode encoding. They are encoded in the Private Use Area in accordance with the proposal of Gaspar Sinai. Kayah Li, Lepcha, Ol Chiki, Saurashtra, Shan, Sinhala, Sundanese, and Vai are encoded according to the not-quite-final draft of Unicode 5.1.
In some cases, both traditional non-place based systems and their modern place-based counterparts are supported. In addition to the specialized Counting Rod and Suzhou numbers, a total of fifteen variants of the "ordinary" Chinese numbers are supported.
The basic interface is from C but a Tcl interface is also provided.
| Language | C, Tcl |
| Dependencies | GMP arbitrary precision arithmetic library |
| Current version | 2.7 |
| Last modified | 2007-12-08 |
| License | GNU Lesser General Public License |
The GNU arbitrary precision arithmetic package GMP is required. The library should work on any POSIX-compliant system on which GMP is available, which means just about any POSIX-compliant system. Kernels on which it is reported to work include: FreeBSD, Linux, Mac OS X, OpenBSD. I would appreciate reports of success or failure on other systems.
The installation process seems not to work properly on OpenBSD. First, the configure script may not detect the presence of GNU MP, even if it is properly installed. Second, the -I and -L flags need to be given to gcc but are not automatically added to the makefile by autoconf. I haven't yet figured out how to make things work automatically on OpenBSD. If you don't know either, please bear with me. If you do know, you might tell me.
Numconv has a manual page. For the library, for the time being, consult the README files and the sample programs in the Examples directory, as well as numconv.c.
If you would like to be notified of new releases, subscribe to libuninum at Freshmeat.
The conversion of Ethiopic strings to numbers is buggy and so has been temporarily disabled. A corrected version is under construction.