
Xlit is a tool for transliteration, that is, converting text from one writing system to another. For instance, if we take a text written in Japanese hiragana like this: ひらがな, and convert it to romanization like this: hiragana, we have transliterated it.
Typical applications include:
Although it may have other applications, Xlit is intended in the first instance for the Ordinary Working Linguist, that is, for professional linguists with only basic computer skills. It is therefore designed to make it very simple to define a new transliteration and to apply it to text. At the same time, it has a number of features that may make it attractive to experts. Perhaps foremost among these is its ability to transliterate only those portions of a text enclosed within designated delimiters.
Using Xlit is very simple. There are four main windows. The two side-by-side at top are used to define the transliteration. The window on the left contains the strings that are to be replaced by the strings on the right. Each pair of strings defines a rule. The number of strings on the left must equal the number of strings on the right.
The other two main windows, by default also arranged side-by-side, are the text windows. The one on the left holds the text to be transliterated. The one on the right holds the result of transliteration.
To perform a transliteration, all we have to do is enter the transliteration definition into the top two windows and load the text to be transliterated, then press the Transliterate menu button.
The File menu provides commands for reading and writing text files and transliteration definitions. Note that transliteration definitions may be read either in one piece or in two pieces. The latter option is convenient when the source and target come from different sources, or where it is easiest to use a specialized editor to enter text in one of the writing systems, then type in the other within Xlit.
It is important to note that the commands that load transliteration definitions and text to be transliterated do NOT clear the window before inserting the new material. This allows material from different sources to be combined. If you want to load a file into a fresh window, you must clear the window explicitly first. Commands for this purpose are found on the Clear menu.
Let's transliterate Ogham into Roman letters. To set up a transliteration definition, we need to create a list of the Ogham letters in Unicode. We could do this in a variety of ways. I used the Unicode editor Yudit to do this. The definition consists of two columns separated by a tab. The first column contains the Ogham letters, the second column their roman transliterations. (Ogham is conventionally transliterated using upper-case letters.)

I saved the Yudit buffer to a file, then read the file into Xlit using the command Load Transliteration Definition.

Next I read in a short Ogham text to be transliterated, using the command Load Text to be Transliterated, resulting in this display:

Then all I had to do was to press the Transliterate menu button for the transliteration to appear.

Transliteration is a more complex problem than it seems at first. The simplest case is when a single character is mapped to some number of other characters. In this case, there is never any question as to what to do. In most cases of greater complexity, one of several issues may arise.
If a rule can apply to its own output or that of another rule, unintended results can occur. For example, suppose that we have the following two rules, which we might intend to exchange A and B:
(a) A -> B (b) B -> A
If we apply (a), then apply (b) to the output, the result will be that all of the original Bs will be changed to As, as intended, but also that all of the original As will remain As, contrary to what was intended. If we apply (b) first, we obtain a similar result, namely that all original As become Bs, as intended, but also that all original Bs remain Bs, contrary to what was intended.
A second example is that of the feeding chain. Suppose that we have the two rules:
(a) A -> B (b) B -> Cand that we apply them in the order (a) followed by (b). The result will be that all As becomes Cs, because (a) creates Bs, which serve as input for rule (b).
The priority problem is the fact that if at least one rule has a domain of size greater than one, the question arises as to which rule to apply to certain sequences: For example, suppose that we have the rules:
(a) A -> D (b) AB -> C
and apply them to the input: EABF. Rule (a) could apply to the A of the input and transform it into D, producing EDBF. Rule (b) could equally well apply to the sequence AB, converting it to C, producing ECF. The result depends on which rule is given the priority of application.
Similar to the Priority Problem is the Directionality Problem. If the input string can be parsed into the input domains of a rule in more than one way, the question arises as to which parse to use. For example:
(a) AA -> B Input: EAAAF Parse: E-A-AA-F yields EABF Parse: E-AA-A-F yields EBAF
Here, there are two ways to parse the input, which produce different results.
The composition problem can be handled by mapping algorithms that behave as if all of the rules were applied simultaneously, so that there is no rule composition. The basic
The priority problem can be addressed by adding to the list of rules a (partial) ordering. The Tcl string mapping primitive assigns priority to rules in the order in which they are specified, so if we supply no other prioritization principle, that is what will happen. In this case, the user can control the results of the mapping by choosing different rule orders.
This can, however, be a tedious and error-prone process. Xlit therefore makes available a priority-determining principle that yields the desired result in a large percentage of cases. This is the principle that rules with longer input domains have priority over rules with shorter input domains. This is implemented by sorting the rules in decreasing order of length of input sequence. Since this does not always yield the desired result, the user may disable it so that he or she may control rule priority explicitly. Whether the rules are prioritized according to their order in the windows or are sorted by input lengt his controlled by the Map Longest First item on the Choices submenu of the Misecellaneous menu.
In the case of a single rule the directionality problem may be addressed by setting the direction in which the string is scanned. In the case of the example above, a left-to-right scan yields the parse E-AA-A-F, resulting in the output EBAF. A right-to-left scan yields the parse E-A-AA-F, resulting in the output EABF. This is, however, not an adequate solution in all cases when the problem results from two rules having overlapping domains, e.g.:
(a) AB -> D
(b) BC -> E
Input: XABCY
Possible results: X-AB-C-Y -> XDCY
X-A-BC-Y -> XAEY
Here direction of scan does not settle the issue. Even if we set the scan from left-to-right, the question arises as to which rule takes priority. It will not do to assign scan directions to rules on an individual bases, since this may produce conflicts.
This problem can be handled by assigning rule priority explicitly or by using larger rule domains and applying the principle that longer rules take priority. The latter approach is illustrated by the following in our example:
(a) ABC -> DC
(b) AB -> D
(c) BC -> E
or:
(a) ABC -> AE
(b) AB -> D
(c) BC -> E
The transliteration may be edited by typing in the two transliteration windows, but for some purposes it is desirable to treat both sides as a unit. The buttons to the right of the transliteration windows provide the ability to do this. The entry boxes above the buttons provide the arguments on which they operate. The Show Entry command highlights the entry whose number is in the lefthand entry box and if necessary brings it into view. Delete Entry deletes the entry. Move Entry moves the entry in the lefthand box so that it immediately precedes the entry specified in the righthand box.
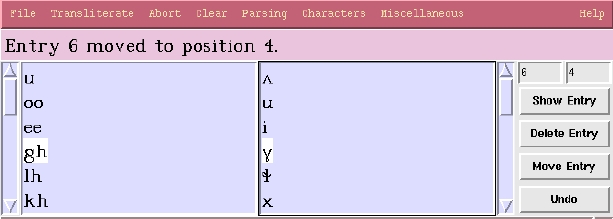
Entry numbers may typed into the entry boxes or entered by clicking in either transliteration window. The number of the entry clicked-on is entered in whichever entry box the user last moved the mouse pointer over.
The Undo button undoes the previous move or deletion. Undo may be invoked any number of times, until all edits have been undone.
Transliteration definitions may be read from files using commands available on the File menu. In Xlit's native format, each line consists of the input string and the string to which the input is to be mapped, separated by a delimiter. By default the delimiter is a tab. An option on the Choices submenu of the File menu changes the delimiter to 0xFDDF. This is an undefined Unicode codepoint, the use of which guarantees that there will be no conflict between a character in the mapping and the delimiter.
Xlit can also use Yudit keymap files as transliteration definitions. In both cases, xlit treats any line beginning with the comment character as a comment. The default comment character is crosshatch (#). A line beginning with a cross-hatch is a comment. The comment character can be changed by giving the first line of the file the form:
#CommentCharacter X
where X is the substitute comment character.
Transliteration definitions may be saved in either the native or Yudit keymap format.
Much of the time how to enter non-ASCII characters is a particular concern when enaged in transliteration. xlit provides a variety of ways to enter characters. You may of course enter characters by typing them. You may be able to enter characters other than the ASCII characters or whatever your basic character set is by means of special keyboard input methods or by remapping your keyboard.
If you already have the necssary characters in a file or in the window of another program, you can read them from the file or copy-and-paste them from the other window.
Since Xlit is intended in large part for linguistic work, widgets are provided for entering the characters of the International Phonetic Alphabet as well as for other characters likely to be needed.

A general Unicode character tool such as gucharmap will allow you to insert any Unicode character. In the illustration below we see xlit in use together with gucharmap. The Cherokee letter A was first selected in the button array. It was then copied into the character accumulation region below, then pasted into xlit, where it can be seen at the beginning of the window for entering the left hand side of character mappings.

If you know a character's code, you can enter it by its code into a widget provided for that purpose. This is useful if you do not have a character map available or are dealing with characters that are difficult to see or for which you lack the font.

If you frequently use a certain set of characters that are not available from the keyboard, you may wish to create a character entry popup of your own. To do this, you will need to find out the Unicode codes for the characters you want to use. Once you have this information, create a plain text file of the following form:
Here is an example:
Greek:4 \u03B1|alpha \u03B2|beta \u03B3|gamma \u03B4|delta \u03B5|epsilon \u03B6|zeta \u03B7|eta \u03B8|theta \u03B9|iota \u03BA|kappa \u03BB|lamda
The first line specifies that the title is to be Greek Letters and that we want four entries per row. The remaining lines each specify one entry in the chart.
Once you have created such a file, go to the Character Entry menu and select the command Load Custom Character Chart Definition. You will be prompted to select a file. Xlit will read this file and create a popup like the one shown below:

Notice that an entry for the new popup has appeared in the Character Entry menu. If you destroy the popup, you can recreate it by clicking on this entry.
You can create as many custom character charts as you like. Note also that sequences of characters are acceptable. If you load the following, your display will become something what is shown below.
Hebrew Letters|3 \u05D0|alef \u05D1|bet \u05D2|gimel \u05D3|dalet \u05D4|he \u05D5|vav \u05D6|zayin \u05D7|het

If you need to transliterate in both directions, or have a mapping in one direction and need to go in the other, it is convenient to be able to invert the mapping. A simple facility for doing this is provided by the Swap Transliteration Input and Output command on the Actions submenu of the Miscellaneous menu. It simply swaps the left-hand and right-hand sides. In most cases you can use the result as is, but note that it will not always behave as desired. Rule interactions will work differently in the inverted mapping; you may find it necessary to change the rule ordering. Furthermore, if the more than one string in the original input maps onto the same string in the original output, the mapping is not invertible. So be careful and look at what you are doing.
In some cases an entire piece of text is to be transliterated, but in other cases only certain portions should be. If the text is divided into matrix and embedded regions by delimiters, it is usually the case that only the embedded text is to be transliterated. However, in some cases it is the matrix text that requires transliteration. Consider, for example, a conversation in a language using a non-roman writing system in the course of which some English is used. In this case, it is most likely the bits in English that will be enclosed within delimiters, but for most purposes it is the non-roman matrix text that will require transliteration.
Xlit defaults to transliterating its entire input, but it may be asked to find and transliterate only certain portions. More specifically, xlit can parse the input into alternating matrix and embedded regions and apply the transliteration only to one or the other. Several delimitation schemes can be handled.
One of the simplest systems for marking embeded text is to enclose it between delimiters that come in pairs, such as parentheses and square brackets. Xlit supports all of the commonly used paired delimiters as well as a number of others. Xlit also supports paired strings, that is, arbitrary strings as opening and closing delimiters.
Any character not otherwise expected to occur in the input can be used as a delimiter. For example, in linguistics, phonologically transcribed data is frequently written between slashes. Xlit allows any character to be designated as an unpaired delimiter.
Xlit also supports XML-style tags. These come in pairs. The opening tag consists of a string of characters enclosed by a less-than sign at the beginning and a great-than sign at the end. The closing tag is the same but for a slash following the less-than sign.
HZ escapes are a device for separating materials in different encodings developed originally for use on the internet. They are also used in some other computational contexts. Unlike most delimitation systems, which were not intended for mechanical processing of the text, HZ escapes provide a means of separating matrix and embedded text unambiguously, without interfering with the use of the delimiters in other contexts in the language. The sequence ~{ initiates an embedded region; the sequence ~} terminates an embedded region. A literal tilde is represented by a sequence of two tildes. A singleton tilde, that is, a tilde followed by any character other than itself, }, {, or newline, is an error. The sequence ~\ at the end of a line serves as a line-continuation marker and is consumed without output. This system allows the delimiters\{ and } to be included in the text, since they only have a special meaning when immediately preceded by a tilde. The sequences tilde \{ and tilde \} are also representable as ~~\{ and ~~\} respectively. HZ escapes were originally proposed as a means of separating English and Chinese text in bilingual documents in RFC 1843.
How the input is parsed is controlled by the parse control panel, shown below:

The first section determines whether transliteration applies to the entire input, only to embedded text, that is, text within delimiters, or only to the matrix text, that is, the text that falls outside of the delimiters.
The second section controls how the input is parsed. In addition to providing a choice of type of delimiter and allowing the particular characters and strings to be specified, it asks whether the parser should abort on encountering ill-formed input or should try to recover. The strict setting causes an immediate abort. In either case, a list of errors will be found in the program journal and in an error popup.
The third section allows you to control what happens to delimited regions once they have been parsed. In some situations, once transliteration is complete the delimiters are no longer needed and should be removed. In others, it is desirable to keep them. This section allows you to specify that the delimiters should be removed (the default) or that they should be retained. If retained, you may keep the same delimiters as in the input or change them.
Note that this means that it is possible to use Xlit to change delimiters even if you do not wish to transliterate anything. You can specify different input and output delimiters without defining any transliteration.
Not infrequently it is convenient to have both a version of something in the original orthography and another version. For example, in linguistic publications concerning languages not written in the Roman alphabet, it is common to give both the original spelling and a transliteration. Xlit can accomodate this by allowing each chunk of embedded text to be duplicated untransliterated either before or after the transliterated material. The duplicate may be bare or it may be surrounded by delimiters chosen from the types available for input.
Duplication of embedded regions is controlled by the Duplication Settings popup.

It is possible to have xlit use a separate program to perform the transliteration. To do this, select Use External Command on the Configuration menu or use the command ExternalCommandList in your initialization file. In both cases, you must specify the command as you would on the command line with the exception that you will not specify the input and output. The command must be one that reads input from the standard input and writes to the standard output.

For example, you could use the tr utility to convert upper case letters to lower case:

If you wanted to set up the same command from your initialization file and to apply it only to regions bounded by angle brackets, you would put the following in your initialization file:
ExternalCommandList {tr [:lower:] [:upper:]}
TransliterateWhat Embedded
ParseChoice PairedCharacter
PairedDelimiter "<>"
OutputDelimiterChoice None
It is possible to have Xlit use a procedure written in Tcl to perform the transliteration. To do this, select Use Plugin on the Configuration menu or use the command LoadPlugin in your initialization file. If you use the GUI, you will be asked to supply the name of the file containing the procedure definition and the name of the procedure. LoadPlugin takes two arguments: the name of the plugin file and the name of the procedure to call.

The plugin procedure must take a string as argument and return a string. You can actually have it do whatever you like - the transformation performed need not be a transliteration. Everything in the plugin file will be executed as Tcl code. You may define ancillary procedures and data structures if you wish.
Plugins are executed by a safe subinterpreter. This means that they cannot manipulate the filesystem or other programs and cannot terminate the program. Plugins may, however, write messages on stderr.
In order to write Tcl plugins you must of course know the Tcl language. Tcl has a very simple syntax, is easy to learn, understands Unicode natively, and provides some handy tools for working with strings, in particular the map subcommand of the string command and a good regular expression substitution command regsub. By way of example, here is a suitable procedure that replaces the German eszet character ß with ss:
proc AscifyEszet {s} {
return [string map {\u00df "ss"} $s]
}
And here is one that implements rot13 encoding:
proc rot13 {s} {
return [string map {a n b o c p d q e r f s g t h u i v j w k x l y m z n a o b p c q d r e s\
f t g u h v i w j x k y l z m A N B O C P D Q E R F S G T H U I V J W K X L Y M Z N A O B P\
C Q D R E S F T G U H V I W J X K Y L Z M} $s]
}
There are a number of situations in which a search cabability is useful when transliterating. Input with delimiters often contains errors - a search tool makes it easier to find them and correct them. If the transliteration is complex, you may not be sure what is happening to some input sequences. Searching for the original in the input text or for possible outputs in the result text can help you to figure out whatis happening.
xlit provides two search tools, each available in both text windows and in both transliteration windows. One of them searches either forward or backword for strings matching a reguular expression. The location of matches is shown both in the Message region and in the label of the search popup. On the left locations are shown in a format in which the line number precedes the character offset within that line. On the right they are shown in terms of the character offset within the input.

Keyboard shortcuts may be defined for most commands available from a menu. A list of the currently defined shortcuts may be obtained from the Help menu. You may define additional shortcuts or override the defaults by defining shortcuts in your initialization file. The command DefineShortcut takes two arguments: the name of the command for which to create a shortcut and a specification of the key combination with which to associate the command. A list of the commands for which shortcuts may be defined is available from the Initialization File submenu of the Help menu.
Key combination specifications are of the form standard in the X Windows system, e.g. <KeyPress-a> for the letter a, <KeyPress-F1> for the first function key, and <Control-a> for the simultaneous combination of the Control key and a. Shortcuts may consist of a sequence of key presses or chords, e.g. <Control-x><Control-s>. For example, to make the simultaneous pressing of the Control key and t execute the transliteration, the initialization file should contain the line:
If you wish you may define multiple keyboard shortcuts for the same command.
On startup, Xlit attempts to read an initialization file called .xlitrc. It looks first in the current working directory, then in the user's home directory. Reading of the init file may be suppressed by giving the command line option -i.
An initialization file consists of a Tcl program. In addition to the primitives of the Tcl language, commands specific to the configuration of Xlit are available. For most purposes you do not need to know anything about programming in general or Tcl in particular - you can just treat the initialization file as a sequence of parameter settings - but you can make use of the Tcl interpreter if you wish to. The initialization file is read by a safe interpreter. This means that some commands and other facilities of the language are made unavailable for security reasons.
A simple initialization file consists of a series of parameter setting commands. Some commands take Boolean arguments, that is, they say yes or no. All such commands have names ending in "P". For example, the command BalloonHelpShowP is used to enable or disable balloon help. If you want to disable balloon help, give the command:
You can use on and off as in this example, or a variety of alternatives, including yes and no, t and f, and 1 and 0.
Other commands take non-Boolean arguments. Examples are:
The first line is a typical color setting. The command name consists of the name of the object followed by the aspect of the object whose color is to be set followed by the word "Color". The single argument of the command is the color. You can use color names like salmon or you can indicate the color you want by specifying its mixture of red, green, and blue. The first line exemplifies this.
A numerical color specification begins with a crosshatch. Since a crosshatch has a special meaning to Tcl, it is preceded by a backslash to give it its ordinary meaning. The main part consists of three groups of two characters. The first group specifies the amount of red, the second the amount of green, and the third the amount of blue. Each pair of characters represents two hexadecimal (base 16) digits. The hexadecimal digits are: 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E, and F. The proportion of each primary color is therefore specified as a number ranging from 00 (0*16 + 0*1 = 0) to FF (15*16 + 15*1 = 240 + 15 = 255).
The next five lines exemplify font settings. The command name indicates what aspect of the program the font is used for and which of the five properties is set. Such commands take a single argument. The choices for slant are roman and italic, for weight normal and bold, and for underlinging normal and underline. Font size is given in points. The font family should be the name of a font family available on your system.
There are just a few things you need to know about Tcl. One is that a crosshatch begins a comment. Any line beginning with a crosshatch will be ignored. It is possible to put comments on the same line as commands, but the rules for this are a bit complicated, so you should avoid doing this unless you learn enough Tcl to understand how comments work.
A second thing that you should know is that certain other characters have a special meaning to Tcl. If you include such characters you may unintentionally be telling Tcl to do something that you did not intend. In Tcl square-brackets enclose a command whose value replaces whatever was between the square brackets. For example, the command:
puts "The current time is [clock format [clock seconds]]."says to print the string The current time is followed by the current time and date. The command [clock seconds] returns the number of seconds since midnight, January 1, 1970. The command [clock format] takes this value and converts it into a string representing the time and date in a more conventional manner. This string becomes part of the overall string. The result looks like this:
If you need to include special characters such as square-brackets in strings and want them to have their ordinary values, you can quote them with a backslash, e.g. \[. Similarly, you can include a space in a string by quoting it with a backslash, e.g.:
Xlit provides several commands to help you with configuration. The command Initialization File Commands on the Help menu provides a complete list of the commands that you can use in your initialization file. You can write the list out to a file or pop it up on the screen.
This list contains only the commands specific to Xlit. You can get a list of the builtin Tcl commands available in the init file interpreter by using the command Initialization File Tcl Commands on the Help menu.
The commands that are built in to Tcl are described in a variety of books and web sites. Probably the best reference manual is to be found at http://aspn.activestate.com/ASPN/docs/ActiveTcl. An excellant list of resources can be found at the Tcl wiki. On a Unix system, the Tcl commands may also be described in a set of manual pages. If so, they will be in section "n". For example, to read the manual page for the Tcl command "string", give the command:
man n stringto your shell.
The command Color Names on the Help menu pops up a list of the available color names.
On the Configuration submenu of the Miscellaneous menu there is a command "Save Configuration". This command writes out a file consisting of init file commands which, if read in as your init file, will recreate the current configuration. Inspecting such a file will give you a good idea of what the arguments to the different commands are and will call to your attention the quoting that is sometimes necessary.
Several command line options allow files to be specified from the command line. These are:
As usual -h provides a summary of usage and -v identifies the program version.
Two flags control the reading of configuration files. The -i flag suppresses reading of tthe initialization file. The -f flag specifies that configuration commands should be read from the specified file instead of the usual initialization file.
The -b flag runs Xlit in batch mode.
Xlit normally runs interactively. It can also run in batch mode. This is useful if you have already got a transliteration set up and wish to apply it to a large number of files or to apply the transliteration under the control of another program. In batch mode the graphical user interface is suppressed. All instructions are taken from a combination of the command line arguments and a configuration file.
To run Xlit in batch mode, call it with the -b command-line flag and use the -t flag to specify the file from which to read the text to be transliterated, and use the -x flag to specify the file from which to read the transliteration definition.
The parse settings must be read from a configuration file. This can be your initialization file, but more likely you will want to use your initialization file to set up the program for interactive use and use another file for batch jobs. The command line flag -f allows you to read configuration commands from a specified file rather than your initialization file.
Here is a suitable configuration file for a delimiter conversion. It converts HZ escapes to XML with the tag ex:
TransliterateWhat embedded ParseChoice HZ OutputDelimiterChoice XML OutputXMLTag ex
Help is available from a number of sources in addition to this reference manual. The Help menu provides information of a variety of types, ranging from where and how to send bug reports to explanations of particular topics.
Most parts of Xlit have balloon help defined. Balloon help consists of windows that pop up when the mouse is left over a region for a certain amount of time. In some cases, balloon help only appears if you linger. In others, it appears immediately.
In some cases more detailed information is needed than is appropriate for balloon help, so clicking the right mouse button will bring up a window with further information.
Xlit is not nearly as fast as a well-written dedicated transliterator written in C. It is probably not an appropriate solution if you need to transliterate very large amounts of text very quickly. However, it is more than fast enough for most purposes.
Xlit is able to handle large numbers of rules and large texts. As a rest of robustness, I loaded the rules necessary to transliterate the Korean Hangul writing system into the romanization used for official purposes by the Republic of Korea. This rule set has 11,239 rules. Xlit had no difficulty with a rule set of this size. For reasonably small texts, even such a large rule set makes little difference. For larger texts, it can take a long time. Running all 11,239 rules on a text of 9,383,073 bytes took 77 minutes on my 1.6 GHz P4 machine.
While transliteration is in progress, a progress bar appears at the right end of the Message region.

Using external commands is relatively slow since there is considerable overhead in repeatedly writing out the data to be processed and creating a child process. Plugins avoid this overhead and so will be faster unless the underlying transformation is one that is much faster in another language (e.g. C) than in Tcl.
Xlit is entirely self-contained, so it should run anywhere that Tcl/Tk is available. It is known to run under GNU/Linux, MS Windows, and Mac OS X. External commands may not work on all systems.